As a data engineer or analyst, you know that data often comes in JSON format. JSON data is nested, which can make it challenging to store in a relational database. While it is possible to store JSON data in a JSON field in a relational database, it is more convenient to analyze it using a flattened format. In this article, we will explain how to achieve this with TABLUM.IO SaaS tool.
Flattening JSON data refers to converting the nested JSON data into a flat table format that can be easily stored in a relational database. When data is flattened, each level of the nested JSON becomes a separate column in the table, and each row represents an individual JSON object. Flattening JSON data is useful because it makes it easier to query and analyze the data.
To demonstrate how to flatten JSON data, we will use the Reddit API to fetch data from the “Data Engineering” subreddit available at https://www.reddit.com/r/dataengineering.json. The data will come in the form of a JSON array.
Flattening JSON data refers to converting the nested JSON data into a flat table format that can be easily stored in a relational database. When data is flattened, each level of the nested JSON becomes a separate column in the table, and each row represents an individual JSON object. Flattening JSON data is useful because it makes it easier to query and analyze the data.
To demonstrate how to flatten JSON data, we will use the Reddit API to fetch data from the “Data Engineering” subreddit available at https://www.reddit.com/r/dataengineering.json. The data will come in the form of a JSON array.

Here is an example of how to fetch the data, parse it, and display it as a flattened table in Python:
import requests
import pandas as pd
url = 'https://www.reddit.com/r/dataengineering.json'
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
data = response.json()['data']['children']
df = pd.json_normalize(data, record_path=['data'])
df = df[['author', 'title', 'created_utc', 'num_comments', 'score']]
print(df)Data engineers and data analysts often face the challenge of extracting relevant information from JSON data and storing it in an SQL table. While the process of loading, parsing, and flattening JSON data can be done using Python, it has a number of downsides, particularly when working with datasets that have different schemas. In order to successfully extract the necessary fields, a software engineer must have a thorough understanding of the schema, which can be time-consuming and inefficient.
However, there is a faster and more efficient solution available: TABLUM.IO. This SaaS tool is designed to:
- fetch JSON or XML data,
- parse it,
- flatten it into a relational form,
- cleanse it from empty nodes,
- filter for excessive and unnecessary columns,
- generate an SQL schema automatically, and
- ingest the resulting data into a ready-to-use database.
Pagination support is a key feature of TABLUM.IO that enables data engineers to retrieve large datasets by making multiple API requests with changing parameters. This feature allows users to overcome the limitations of API response limits, which can be a significant challenge when working with large volumes of data. By breaking down the data into smaller segments and retrieving it via multiple requests, data engineers can ensure that they are able to retrieve all the data they need.
Once the data has been retrieved, TABLUM.IO automatically concatenates the results into a single SQL table, making it easy for users to analyze the data as a whole.
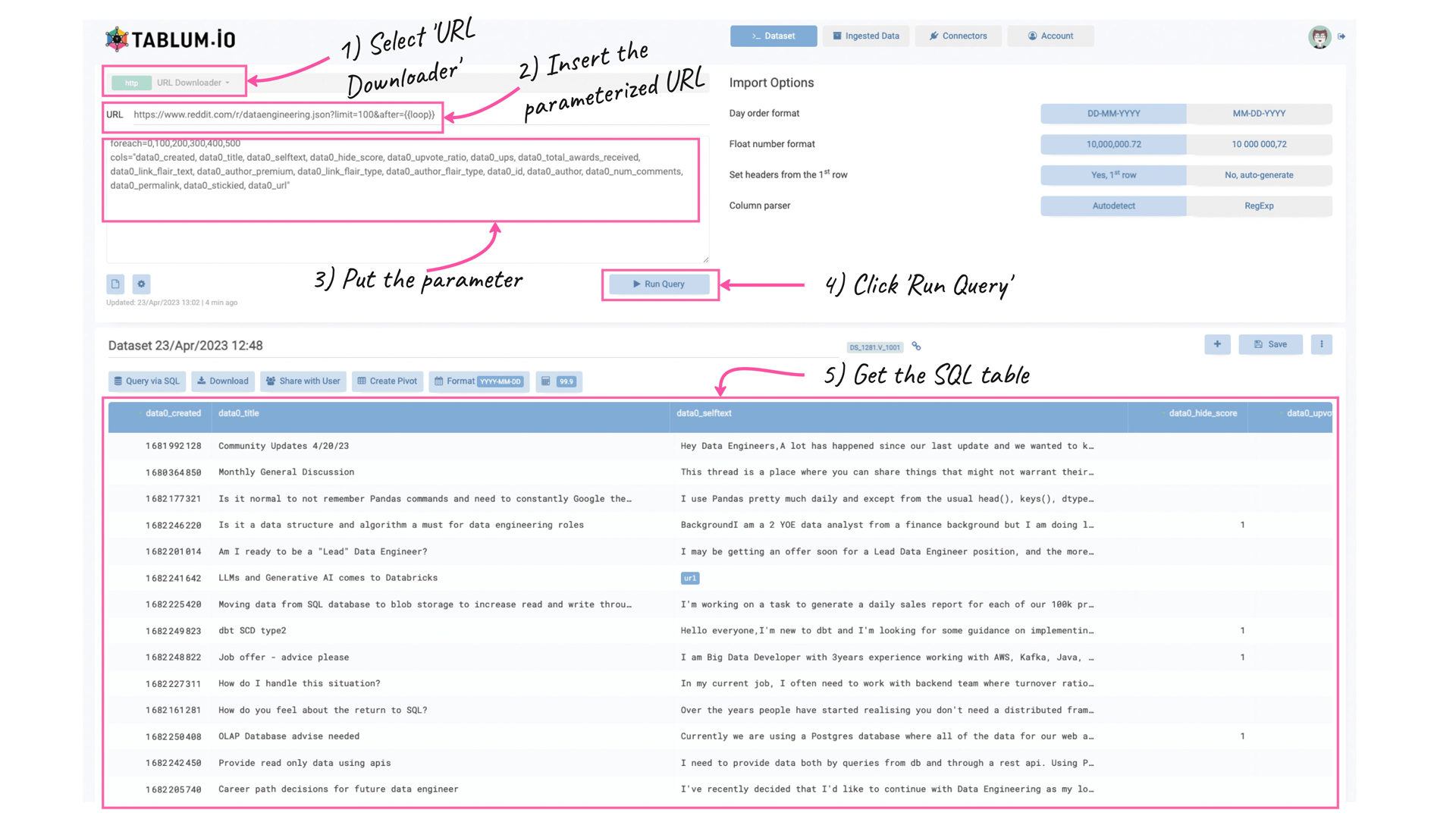
To illustrate the data retrieval process in TABLUM.IO, we used the "URL Downloader" connector and provided the following parameterized URL to fetch data from a subreddit with pagination:
https://www.reddit.com/r/dataengineering.json?limit=100&after={{loop}}We also provided extra parameters to the “URL Downloader” to extract the 600 most recent records, with a limit of 100 items per request. These parameters included the following:
foreach=0,100,200,300,400,500
cols="data0_created, data0_title, data0_selftext, data0_hide_score, data0_upvote_ratio, data0_ups, data0_total_awards_received, data0_link_flair_text, data0_author_premium, data0_link_flair_type, data0_author_flair_type, data0_id, data0_author, data0_num_comments, data0_permalink, data0_stickied, data0_url"The "cols" parameter was used to keep only the necessary columns in the resulting SQL table and set the order of the columns. This helps to ensures that only the relevant information is retained for analysis and it is represented in the right way. See the description of the parameters in this article.
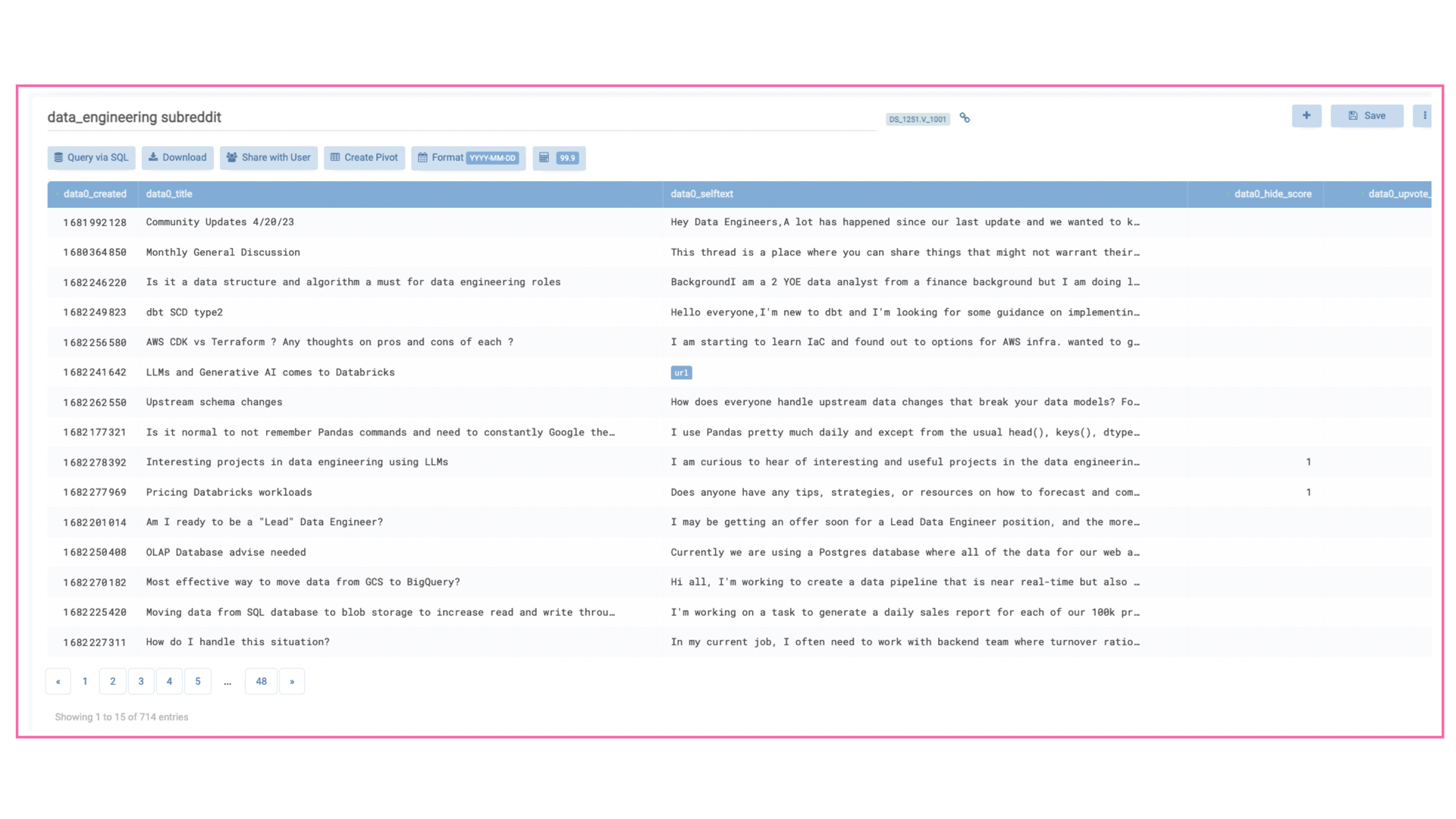
It also worth noting, that the SQL database is already a part of TABLUM.IO, which means that data engineers can access it using the TABLUM.IO SQL Console in the UI, or via any 3rd party BI software using a common database connection to TABLUM.IO.
E.g. in the example above, we can query the most upvoted posts with the following SQL command (ClickHouse SQL dialect):
E.g. in the example above, we can query the most upvoted posts with the following SQL command (ClickHouse SQL dialect):
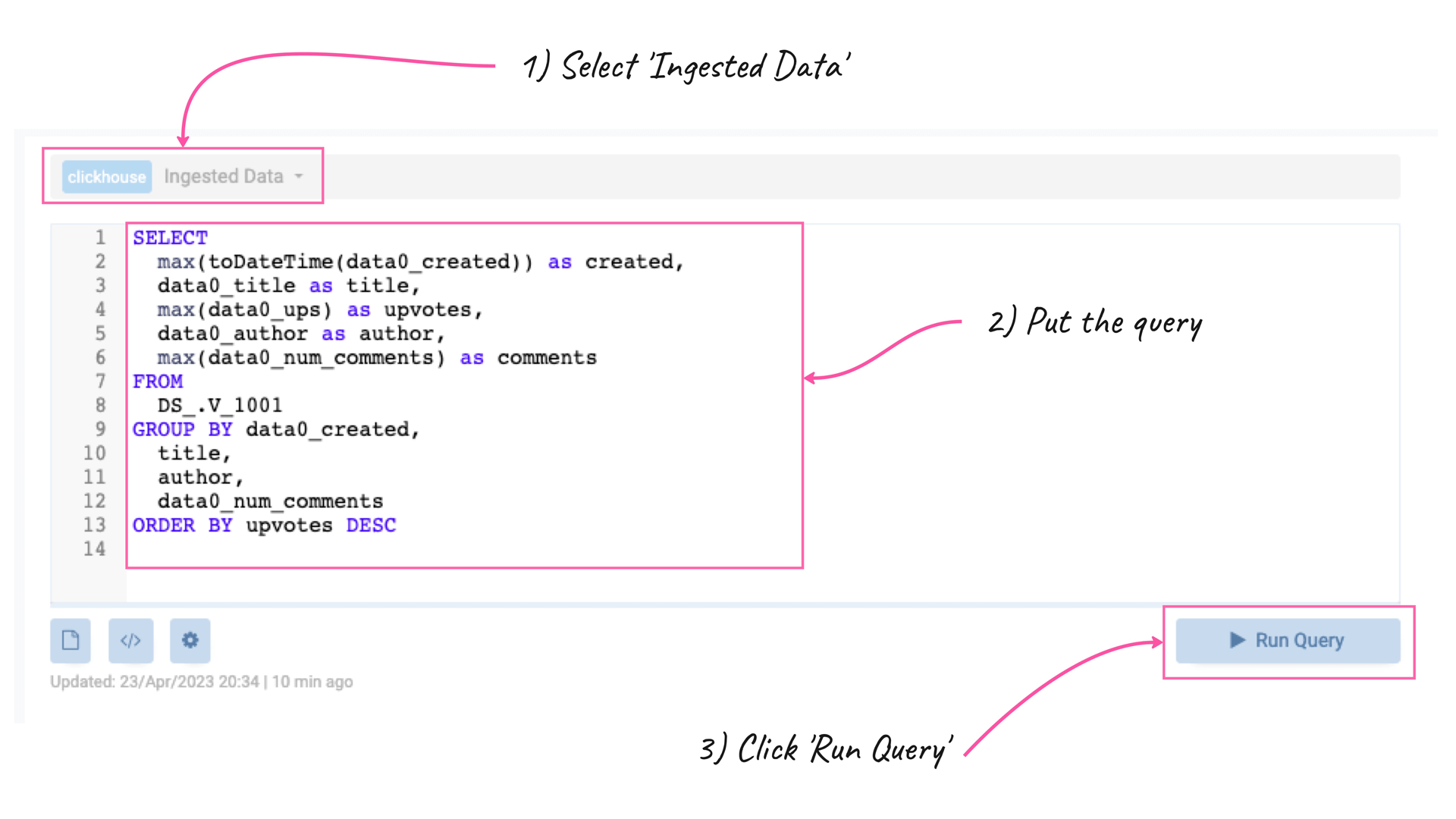
SELECT
max(toDateTime(data0_created)) as created,
data0_title as title,
max(data0_ups) as upvotes,
data0_author as author,
max(data0_num_comments) as comments
FROM
DS_.V_1001
GROUP BY data0_created,
title,
author,
data0_num_comments
ORDER BY upvotes DESC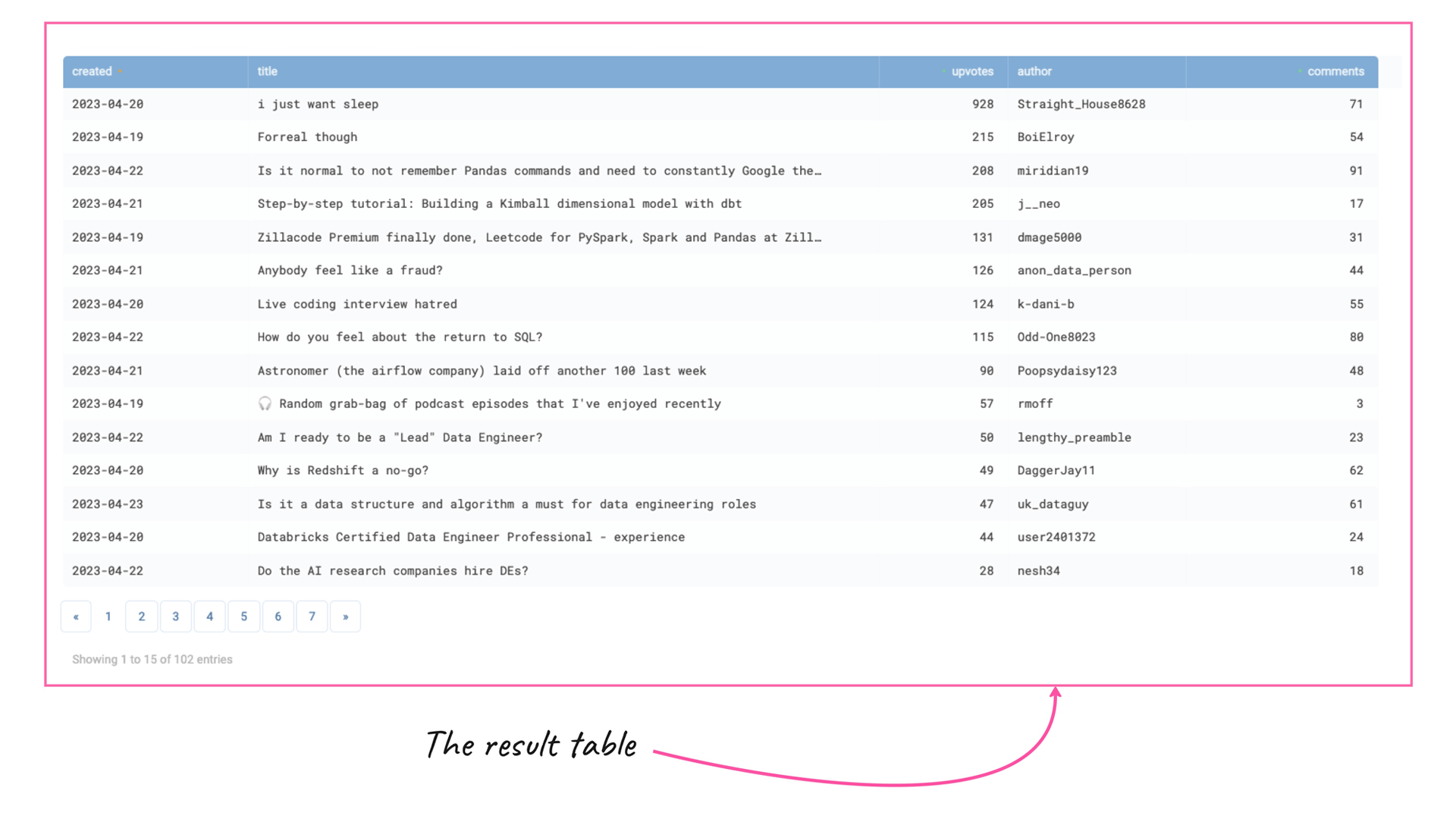
One of the key benefits of using TABLUM.IO is that it simplifies the process of data ingestion, making it faster and more efficient. This is because the platform automatically takes care of many of the more time-consuming aspects of data flattening, such as schema generation and data cleansing. As a result, data engineers can focus on analyzing the data, rather than spending their time on data preparation.
Using TABLUM.IO SaaS to flatten JSON data makes it easy to implement the entire workflow from RESTful API to analytics-ready SQL table with access from other business intelligence software or data apps. With TABLUM.IO SaaS, you can flatten JSON data in a matter of minutes and start analyzing your data quickly and easily.
In conclusion, flattening JSON data is an essential step in analyzing JSON data in a relational database. While it is possible to do this in Python and other scripting languages, using a tool like TABLUM.IO SaaS makes the process much easier and faster. With TABLUM.IO SaaS, you can flatten JSON data, filter out unnecessary columns, and ingest it into a ready-to-use database in just a few clicks. This makes it easy to analyze your JSON data and derive insights quickly and easily.
Now it is time to try it by yourself at https://go.tablum.io.
Using TABLUM.IO SaaS to flatten JSON data makes it easy to implement the entire workflow from RESTful API to analytics-ready SQL table with access from other business intelligence software or data apps. With TABLUM.IO SaaS, you can flatten JSON data in a matter of minutes and start analyzing your data quickly and easily.
In conclusion, flattening JSON data is an essential step in analyzing JSON data in a relational database. While it is possible to do this in Python and other scripting languages, using a tool like TABLUM.IO SaaS makes the process much easier and faster. With TABLUM.IO SaaS, you can flatten JSON data, filter out unnecessary columns, and ingest it into a ready-to-use database in just a few clicks. This makes it easy to analyze your JSON data and derive insights quickly and easily.
Now it is time to try it by yourself at https://go.tablum.io.
