With the rise of APIs in modern development, data retrieval and storage have become an integral part of data analytics. Efficiently fetching data from APIs and storing it in a structured format, such as a relational database, is a critical step in data preparation and analysis. In this article, we will examine the process of pulling data from any API endpoint (e.g. REST API, SOAP, custom HTTP-based interface) and storing it in a relational database without the need for manual coding.
We will be using TABLUM.IO – a service designed to streamline the process of converting raw unstructured data pulled from APIs into analysis-ready SQL tables.
We will be using TABLUM.IO – a service designed to streamline the process of converting raw unstructured data pulled from APIs into analysis-ready SQL tables.
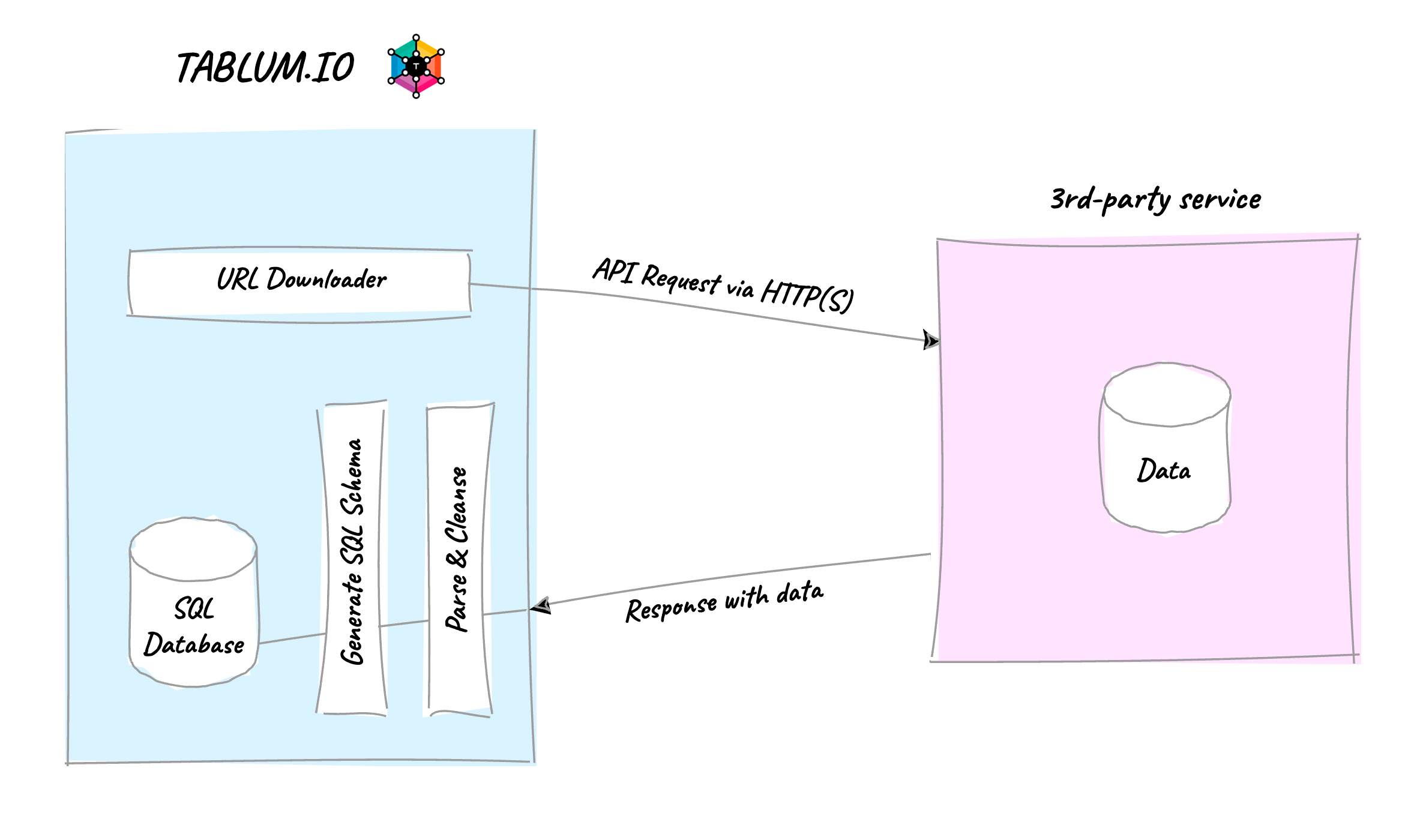
The diagram above illustrates the general workflow for accessing data through TABLUM.IO. The platform uses an embedded HTTP client, URL Downloader, to fetch data from third-party services. The data is then parsed, cleansed, transformed, and loaded into internal SQL storage powered by ClickHouse. All of these steps are automated, including SQL schema generation. Once the request is complete, the data is stored in a SQL table with the corresponding schema based on the received data.
TABLUM.IO reads and parses various data formats in API responses, detecting them based on the returned MIME type or file extension:
All nested formats, such as JSON and XML, will be automatically de-nested into a relational format with 2-level nesting support. TABLUM.IO accurately recognizes data formats, numeric values, and specific data types, such as currency and percent values, in the resulting data.
It’s time to fetch some data and see how it works.
We will start with Github RESTful API. Let’s fetch the list of the latest commits from the Metabase repository.
The URL for the quest is:
TABLUM.IO reads and parses various data formats in API responses, detecting them based on the returned MIME type or file extension:
- JSON data
- XML data (including RSS and ATOM)
- CSV data (comma separated)
- TSV (tab separated)
- MS Excel binary
- MS Excel new format
All nested formats, such as JSON and XML, will be automatically de-nested into a relational format with 2-level nesting support. TABLUM.IO accurately recognizes data formats, numeric values, and specific data types, such as currency and percent values, in the resulting data.
It’s time to fetch some data and see how it works.
We will start with Github RESTful API. Let’s fetch the list of the latest commits from the Metabase repository.
The URL for the quest is:
https://api.github.com/search/commits?q=metabase&per_page=100&page=1If we open it in the browser, we can see that the result is a dataset in JSON format:
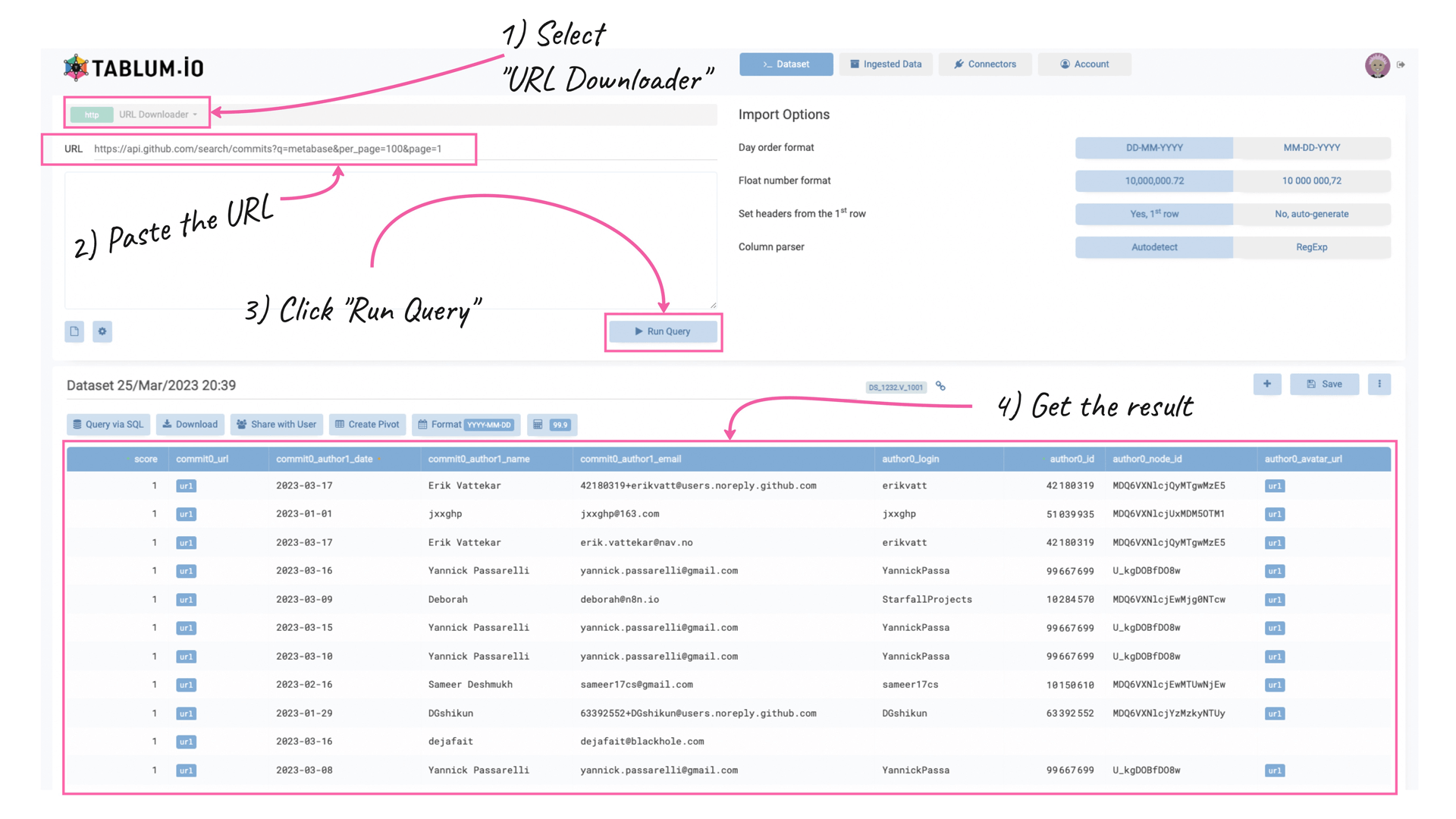
In a couple of seconds, you will see the result of the query as a spreadsheet. It means the data was successfully pulled, parsed, de-nested, and stored in the database.
Prior to data ingestion, TABLUM.IO generates an SQL schema for the data based on the content of corresponding columns: DateTime64 for dates, Int64 for integer numbers, Float64 for float numeric values, and String for the rest data. The data is cleansed before it is added to the SQL table, so all dates and numeric values will be normalized automatically.
Often, there’re too many fields returned by the API request, so you may want to alter the number of columns in the output. You can list them using the parameter “cols” in the parameter box underneath the URL field. Let’s filter out everything except the following columns:
- commit0_author1_date,
- repository0_full_name,
- commit0_author1_name,
- author0_login,
- commit0_author1_email,
- committer0_login
We shall put the following parameters in the parameter box:
cols="commit0_author1_date, repository0_full_name, commit0_author1_name, author0_login, commit0_author1_email, committer0_login"and click on the “Run Query” button again.
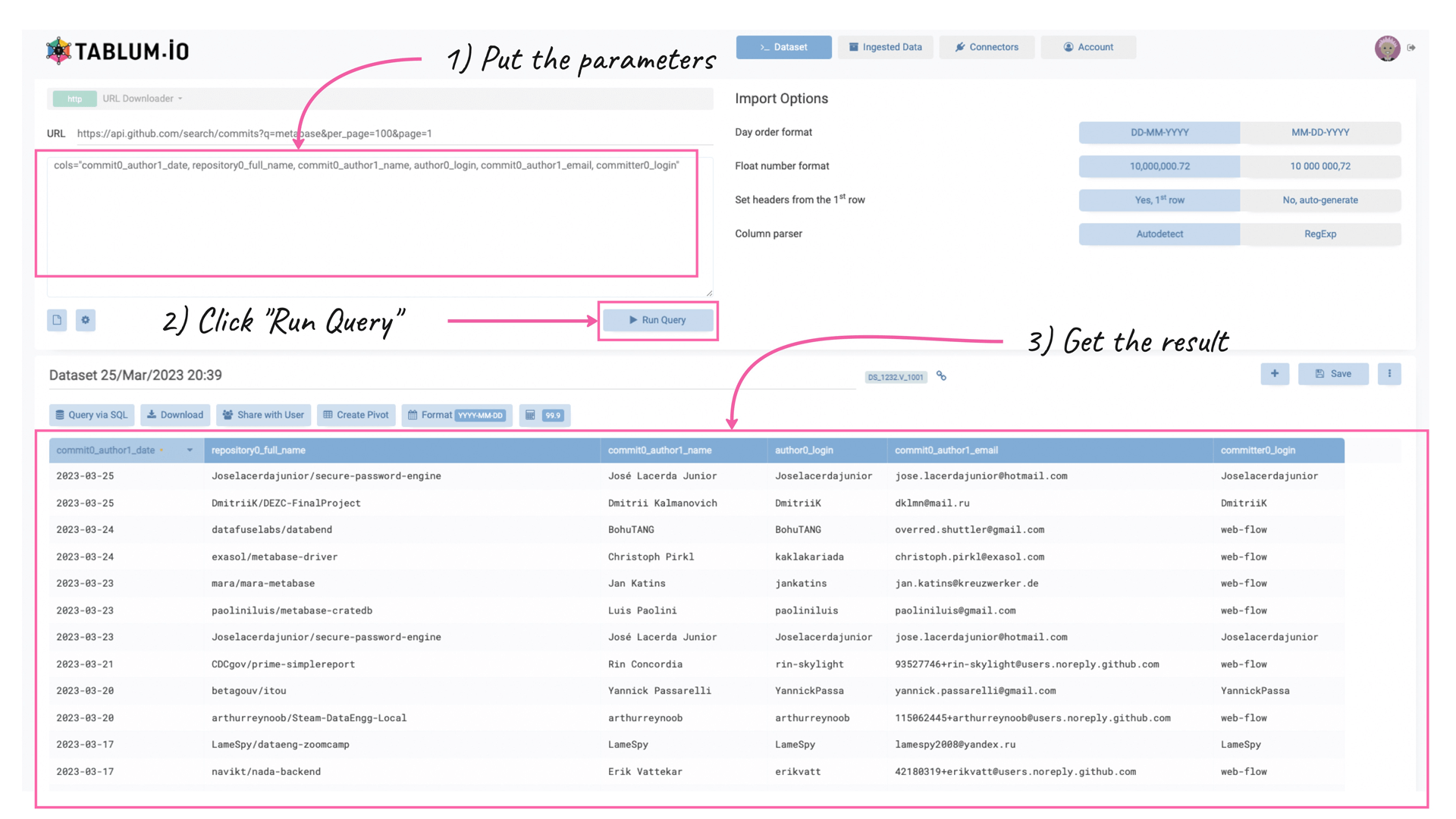
As you can see, TABLUM.IO kept only the listed columns in the resulting table.
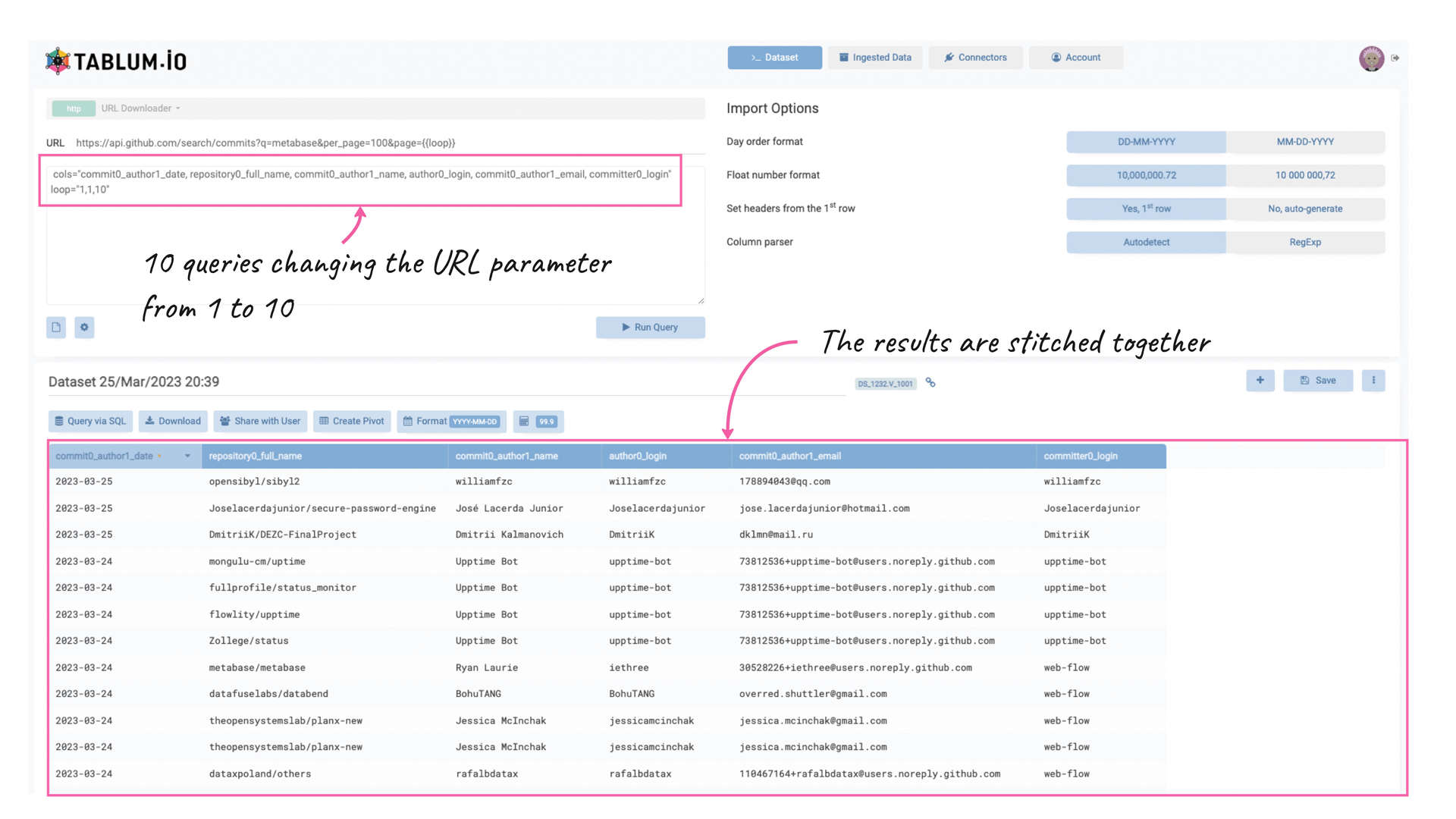
What if we need to fetch data through a series of requests? For example, we want to pull 1000 items from the GitHub API (10 pages per 100 items). Then, we should use loops.
This is what we shall put in the URL field:
What if we need to fetch data through a series of requests? For example, we want to pull 1000 items from the GitHub API (10 pages per 100 items). Then, we should use loops.
This is what we shall put in the URL field:
https://api.github.com/search/commits?q=metabase&per_page=100&page={{loop}}And enter the following in the parameter box:
cols="commit0_author1_date, repository0_full_name, commit0_author1_name, author0_login, commit0_author1_email, committer0_login"
loop="1,1,10"TABLUM.IO will run ten queries, changing the URL parameter from 1 to 10, and then automatically stitch the results together.
There's another option in TABLUM.IO for loops – to use enumerated loops that will iterate through the specified list of parameters. For example, we might want (for some reason) to pull commit history for two components: ClickHouse and Metabase.
Then we should use the following URL: https://api.github.com/search/commits?q={{loop}}&per_page=100&page=1
And the following parameters:
cols="commit0_author1_date, repository0_full_name, commit0_author1_name, author0_login, commit0_author1_email, committer0_login"
foreach="clickhouse,metabase"Thus, now the changing parameter in the URL is "q". There will be two requests with "?q=clickhouse" and "?q=metabase". Once they're done, TABLUM.IO will stitch the results together and ingest data into a table.
There are a few other useful parameters that you may want to use while fetching data via API.
- extract=”<column name>,<regular expression>”
E.g. by adding the following parameter to the request, you will keep only the first name in the commit0_author1_name column.
extract="commit0_author1_name,(\w+)"- header=”<header name>: <header value>”
It allows you to add a custom HTTP header to the request. E.g. Authorization field, or authentication token.
header='Authorization: Basic XXXXXXXXXXX'Note, that multiple “header” entries can be added.
There’re a few variables, that can be used in the parameterized URL to make life easier.
The parameterized URL is useful specifically for cases when you want to pull data from APIs on a regular basis, e.g. daily or weekly. Thus, you can specify the parameterized URL and configure the refresh interval as it’s shown below:
Let’s take a look at another example – the CurrencyApi. In order to fetch the recent currency rates for EUR-to-<currency> on a daily basis, we shall configure it in the following way:
There’re a few variables, that can be used in the parameterized URL to make life easier.
- {{day}} – will be replaced with the current day (e.g. for December 20, 2023 it will be 20)
- {{month}} – will be replaced with the current month (e.g. for December 20, 2023 it will be 12)
- {{year}} – will be replaced with the current year (e.g. for December 20, 2023 it will be 2023)
- {{yesterday}}, {{last_month}}, {{last_year}} – same as above, but for the previous interval.
The parameterized URL is useful specifically for cases when you want to pull data from APIs on a regular basis, e.g. daily or weekly. Thus, you can specify the parameterized URL and configure the refresh interval as it’s shown below:
Let’s take a look at another example – the CurrencyApi. In order to fetch the recent currency rates for EUR-to-<currency> on a daily basis, we shall configure it in the following way:
https://api.currencyapi.com/v3/historical?date={{year}}-{{month}}-{{yesterday}}&base_currency=EUR¤cies=USD,CAD,AUDRequest Parameters:
header="apikey: IFVCBZ1mzf103vNNxmDXqM4n41oG62E6VioJ12KG"
root="data"(do not forget to replace the API key with yours)
And, finally, you need to click on the Cog icon and select “Every day” in the update period dropdown.
And, finally, you need to click on the Cog icon and select “Every day” in the update period dropdown.
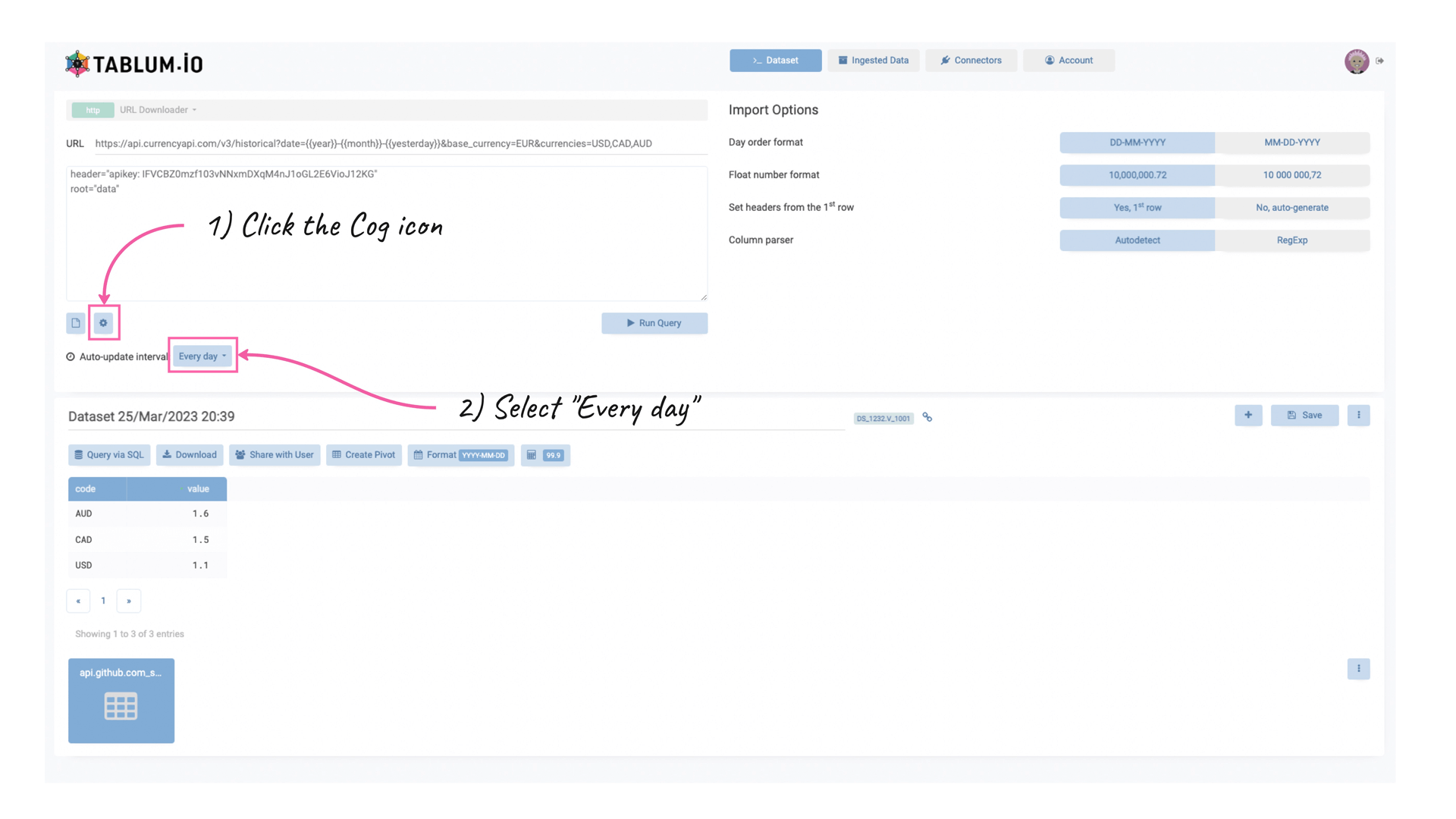
So, it will start fetching data using historical currency exchange rates daily, using the parameterized URL with yesterday’s date (because it’s historical API).
You may notice a new parameter – “root” that has not yet been explained earlier. It is the root node in the nested structures (XML, JSON). In most cases, TABLUM.IO will find the best root node automatically, but when the number of leaves is low, it may be confused so it is better to specify the root node explicitly. In our case, the correct root node of the nested structure is “data”.

Despite its excellent API fetching capabilities, TABLUM.IO is also great at loading data from files and other datasets in JSON, XML, CSV, and TSV over HTTP (e.g., using URLs). You may want to use it for RSS feed parsing, loading data from remote files, etc. All these cases will be handled in a similar way: the data will be parsed, cleansed, normalized, and ingested into the TABLUM internal SQL database. Ultimately, you will get analysis-ready tables created from raw and unstructured data without writing a line of code.
OK, the data is loaded, what's next? Now you can share the database content with your team or explore and visualize the data in your favorite business intelligence software using a standard database connector that TABLUM.IO will provide.
