Navigating the maze of Large Language Models (LLMs) for local inference on personal computing hardware or private servers can be a challenge given their rapid evolution. Your choice should be influenced by factors such as the model’s performance metrics, its rate of inference, and its compatibility with both your hardware and the chosen frameworks.
The performance of LLMs is commonly gauged by their ranking on reliable platforms like the Open LLM leaderboard on HuggingFace. Although the swift release of new models sometimes leads to a lag in their appearance on this leaderboard, it remains a trustworthy reference for high-performing models.
The significance of inference speed varies with your project’s requirements. For tasks such as batch processing where time is not of the essence, a slower model may suffice. Conversely, for real-time applications like chat interfaces, quick responses are critical to a satisfactory user experience.
This is where hardware acceleration technologies come into their own. CUDA for NVIDIA GPUs and Metal for Apple devices can considerably boost inference speed. However, it is essential to opt for models that can effectively use these technologies and have robust support from established frameworks like llama.cpp or MLC-LLM. Models lacking solid framework support often aren’t worth the effort and time of adaptation, as improved models or alternatives will eventually become available.
Regarding hardware compatibility, your model of choice should be as large as your system’s memory permits, since larger models tend to deliver superior performance. One area where benchmarks often fall short is in representing the trade-off between base model size and quantization — a method to reduce memory usage. To fill this gap, consider creating a task-specific mini-benchmark for evaluation. Use it to test several models and determine the best balance between size and performance.
In certain cases, system constraints may dictate the use of frameworks that can offload some operations to the CPU or distribute the model across multiple accelerators. This flexibility can provide acceptable operating speeds even when a significant portion of the model is on your accelerator. Such alternatives can be invaluable when dealing with hardware limitations.
As for the underlying architecture of the LLM, it is less of a concern for an end user. Your focus should be on aspects like model quality, memory usage, and speed, as well as the supporting frameworks. While there are numerous models available, many are modifications of a few base models, primarily built using the transformer architecture. This simplifies matters, as most transformer-based models can operate efficiently on almost any hardware using one of the three backend frameworks: TensorFlow, PyTorch, or JAX.
Support for CUDA/Metal is crucial when selecting an LLM. MLC-Chat stands out for its extensive support for native acceleration across a variety of hardware types. However, llama.cpp, while supporting fewer platforms, offers more features and is a close second.
Selecting the right LLM is an iterative procedure. Begin by setting up the necessary frameworks and running them on your system. Pay attention to the memory usage and identify the high-ranking leaderboard models compatible with your frameworks. From this shortlist, conduct an A/B test on your task. This process will guide you in selecting the most suitable model for your needs.
Selecting an LLM for your project entails careful evaluation and some experimentation. By focusing on the model’s performance, speed, hardware compatibility, and the supporting frameworks, you can identify an LLM that best suits your requirements. Additions and updates to these guidelines may be necessary as this rapidly evolving field continues to unfold and push the boundaries.
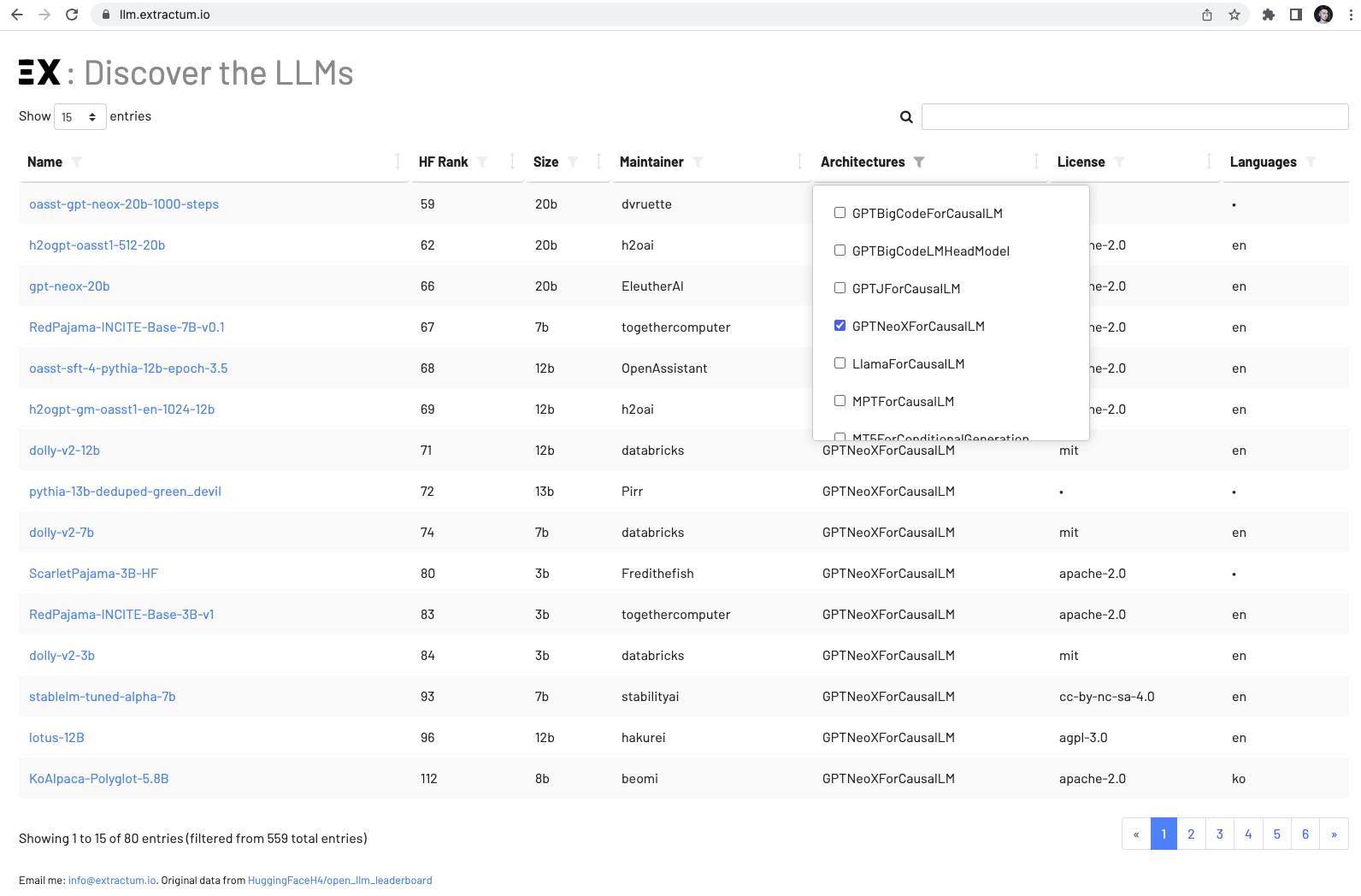
Selecting the ideal Large Language Model for local inference, once a tedious and time-consuming task, is now a breeze with TABLUM’s LLM Explorer. Available at http://llm.extractum.io, this dynamic online tool streamlines the discovery, comparison, and ranking of the vast array of LLMs available.
Its user-friendly interface allows you to filter models by various factors such as architecture, language, and context length, making the selection process simple and efficient. It doesn’t matter if you’re a seasoned machine learning researcher, a budding developer, or an AI enthusiast, LLM Explorer provides indispensable insights to find the best-fit LLM for your needs.
The performance of LLMs is commonly gauged by their ranking on reliable platforms like the Open LLM leaderboard on HuggingFace. Although the swift release of new models sometimes leads to a lag in their appearance on this leaderboard, it remains a trustworthy reference for high-performing models.
The significance of inference speed varies with your project’s requirements. For tasks such as batch processing where time is not of the essence, a slower model may suffice. Conversely, for real-time applications like chat interfaces, quick responses are critical to a satisfactory user experience.
This is where hardware acceleration technologies come into their own. CUDA for NVIDIA GPUs and Metal for Apple devices can considerably boost inference speed. However, it is essential to opt for models that can effectively use these technologies and have robust support from established frameworks like llama.cpp or MLC-LLM. Models lacking solid framework support often aren’t worth the effort and time of adaptation, as improved models or alternatives will eventually become available.
Regarding hardware compatibility, your model of choice should be as large as your system’s memory permits, since larger models tend to deliver superior performance. One area where benchmarks often fall short is in representing the trade-off between base model size and quantization — a method to reduce memory usage. To fill this gap, consider creating a task-specific mini-benchmark for evaluation. Use it to test several models and determine the best balance between size and performance.
In certain cases, system constraints may dictate the use of frameworks that can offload some operations to the CPU or distribute the model across multiple accelerators. This flexibility can provide acceptable operating speeds even when a significant portion of the model is on your accelerator. Such alternatives can be invaluable when dealing with hardware limitations.
As for the underlying architecture of the LLM, it is less of a concern for an end user. Your focus should be on aspects like model quality, memory usage, and speed, as well as the supporting frameworks. While there are numerous models available, many are modifications of a few base models, primarily built using the transformer architecture. This simplifies matters, as most transformer-based models can operate efficiently on almost any hardware using one of the three backend frameworks: TensorFlow, PyTorch, or JAX.
Support for CUDA/Metal is crucial when selecting an LLM. MLC-Chat stands out for its extensive support for native acceleration across a variety of hardware types. However, llama.cpp, while supporting fewer platforms, offers more features and is a close second.
Selecting the right LLM is an iterative procedure. Begin by setting up the necessary frameworks and running them on your system. Pay attention to the memory usage and identify the high-ranking leaderboard models compatible with your frameworks. From this shortlist, conduct an A/B test on your task. This process will guide you in selecting the most suitable model for your needs.
Selecting an LLM for your project entails careful evaluation and some experimentation. By focusing on the model’s performance, speed, hardware compatibility, and the supporting frameworks, you can identify an LLM that best suits your requirements. Additions and updates to these guidelines may be necessary as this rapidly evolving field continues to unfold and push the boundaries.
Selecting the ideal Large Language Model for local inference, once a tedious and time-consuming task, is now a breeze with TABLUM’s LLM Explorer. Available at http://llm.extractum.io, this dynamic online tool streamlines the discovery, comparison, and ranking of the vast array of LLMs available.
Its user-friendly interface allows you to filter models by various factors such as architecture, language, and context length, making the selection process simple and efficient. It doesn’t matter if you’re a seasoned machine learning researcher, a budding developer, or an AI enthusiast, LLM Explorer provides indispensable insights to find the best-fit LLM for your needs.
