The Role of TABLUM.IO in Solving the Challenges of Unstructured and Semi-Structured Data
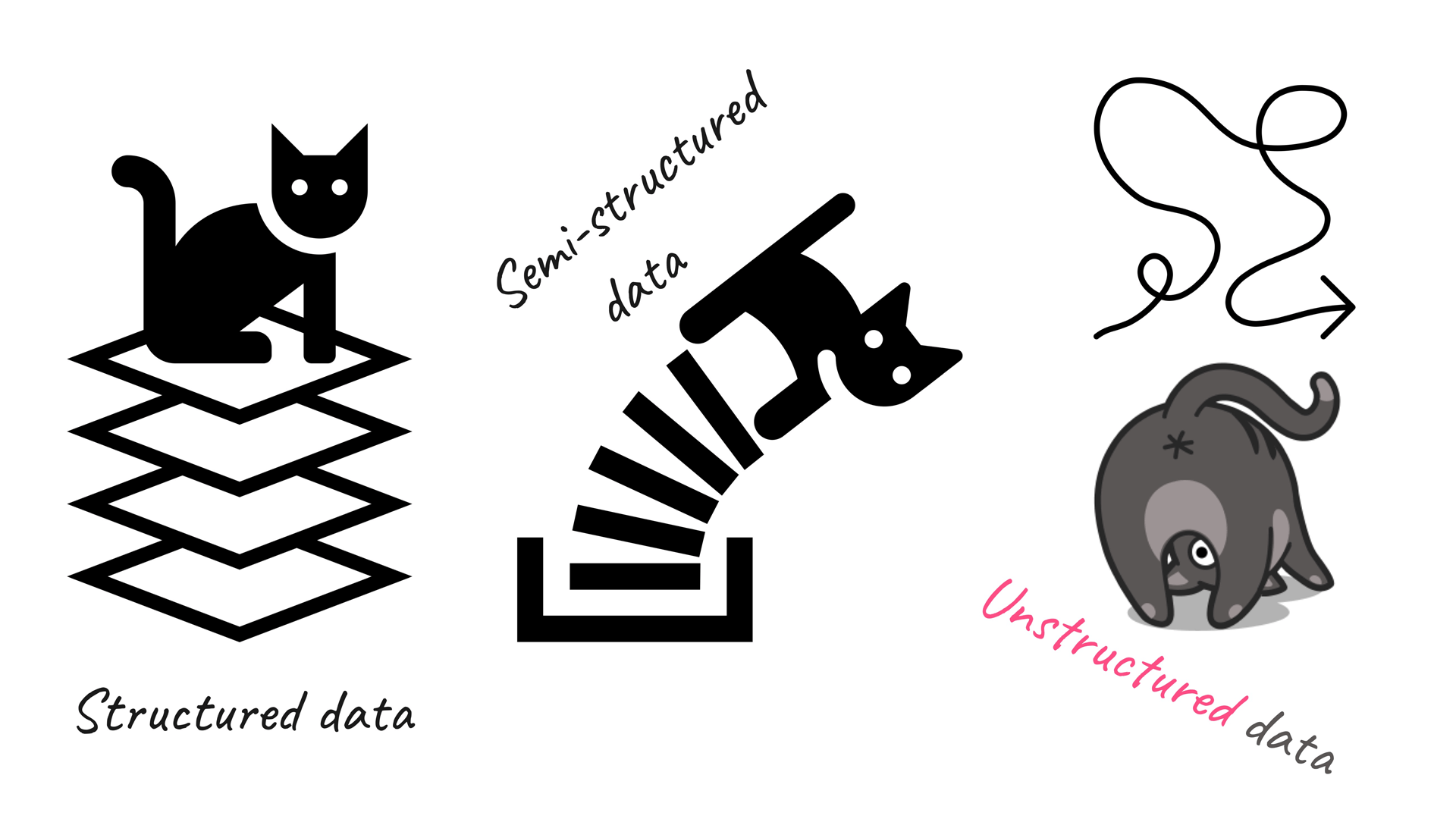
In today's data-driven world, data comes in various forms, and each type poses a different set of challenges to data professionals. There are three main types of data: structured, unstructured, and semi-structured.
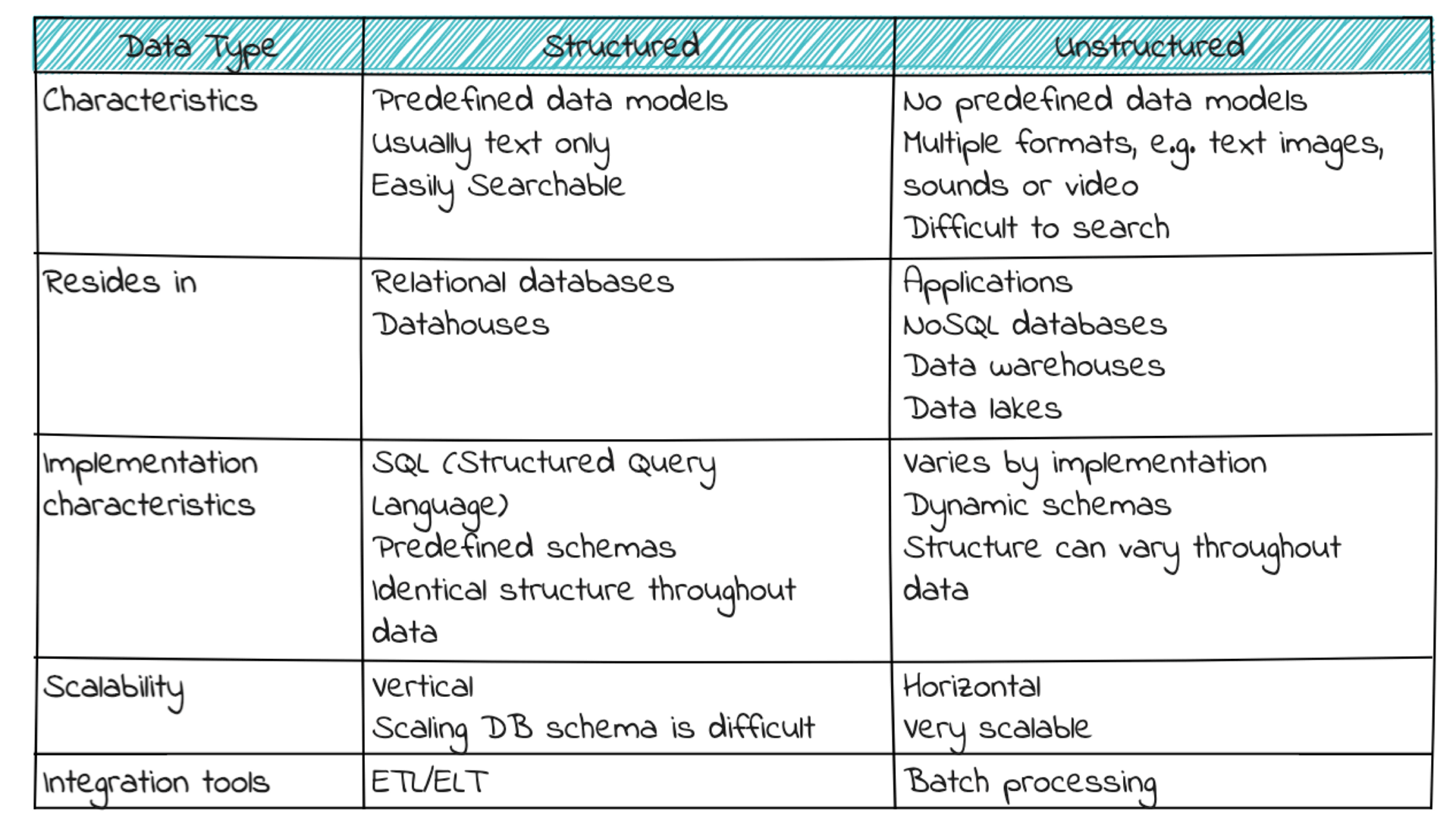
Structured data is like a well-organized bookshelf, where each book has a clearly defined title, author, and genre. In the world of data storage, structured data follows a similar concept: it's predefined and formatted to fit a specific structure before being stored. This process is known as schema-on-write, and it's the backbone of the relational database.
Structured data is highly organized, precise, and quantitative. It consists of measurable numerical values such as numbers, dates, and times, making it easy to analyze and search for specific information. It's no wonder that SQL, the structured query language, is the go-to programming language for managing structured data.
Unstructured data lacks a predefined format or organization, which makes it more challenging to collect, process, and analyze than structured data. Unlike structured data, it has no set format or organization, making it harder to process and analyze. It can come in many forms, from emails and social media posts to sensor data and satellite imagery. However, with the right tools and techniques, unstructured data can reveal valuable insights into customer behavior, market trends, and compliance issues. While unstructured data may be challenging, it offers enormous potential for organizations that can harness its power.
Structured data is like a well-organized bookshelf, where each book has a clearly defined title, author, and genre. In the world of data storage, structured data follows a similar concept: it's predefined and formatted to fit a specific structure before being stored. This process is known as schema-on-write, and it's the backbone of the relational database.
Structured data is highly organized, precise, and quantitative. It consists of measurable numerical values such as numbers, dates, and times, making it easy to analyze and search for specific information. It's no wonder that SQL, the structured query language, is the go-to programming language for managing structured data.
Unstructured data lacks a predefined format or organization, which makes it more challenging to collect, process, and analyze than structured data. Unlike structured data, it has no set format or organization, making it harder to process and analyze. It can come in many forms, from emails and social media posts to sensor data and satellite imagery. However, with the right tools and techniques, unstructured data can reveal valuable insights into customer behavior, market trends, and compliance issues. While unstructured data may be challenging, it offers enormous potential for organizations that can harness its power.
Semi-structured data is data that has some form of organization but doesn't conform to a rigid data model or schema. It contains some organizational properties such as semantic tags and metadata that provide some structure, making it easier to analyze than unstructured data. However, unlike structured data, it does not have a fixed schema, which makes it more flexible and scalable.
Semi-structured data is commonly found in JSON and XML documents, as well as in key-value stores and graph databases. Examples of semi-structured data include social media posts, emails, and sensor data. Overall, semi-structured data falls between the structured and unstructured data categories, providing a balance between organization and flexibility.
Challenges of Working with Unstructured and Semi-Structured Data for Data Engineers
Working with unstructured and semi-structured data can be a daunting task for data engineering professionals due to the inherent variability of these data types. Ingesting data from multiple sources like flat files and API responses requires specialized skills, tools, and processes that can be both time-consuming and intricate. Moreover, managing large amounts of unstructured data can be expensive and challenging due to the need for more storage and computing resources.
Unstructured data lacks a predefined structure, making it difficult to process and analyze, while semi-structured data presents challenges due to its incomplete schema. This requires custom data preparation tasks, which can be complex and require specialized expertise. These challenges highlight the importance of effective data management and the need for skilled data professionals who can work with these types of data.
Unstructured data lacks a predefined structure, making it difficult to process and analyze, while semi-structured data presents challenges due to its incomplete schema. This requires custom data preparation tasks, which can be complex and require specialized expertise. These challenges highlight the importance of effective data management and the need for skilled data professionals who can work with these types of data.
TABLUM.IO: A Solution for Managing Flat Files in Data Engineering Projects
TABLUM.IO offers a solution to these challenges by providing a user-friendly, cloud-based data preparation and management platform that enables data professionals to easily transform, cleanse, and normalize large amounts of data from multiple sources. TABLUM.IO allows users to connect to various types of data sources and automatically turn any raw dataset into relational databases.
The tool offers several advantages over using custom Python scripts for data preparation tasks. While Python scripts can be useful for data analysis, not all data engineers have the programming skills or may find it time-consuming to create scripts from scratch. TABLUM.IO streamlines and automates many data engineering tasks, making the data preparation process more efficient and less time-consuming.
In terms of data schema detection, TABLUM.IO is a standout tool that sets it apart from other low-code ETL tools. It doesn't require the installation, configuration, and maintenance of a separate solution. Instead, TABLUM.IO can be used out of the box with ease, and its schema generation capabilities make it faster and more efficient for data ingestion.
Overall, TABLUM.IO is a user-friendly and efficient tool for data engineers and analysts to prepare and transform their data.
The tool offers several advantages over using custom Python scripts for data preparation tasks. While Python scripts can be useful for data analysis, not all data engineers have the programming skills or may find it time-consuming to create scripts from scratch. TABLUM.IO streamlines and automates many data engineering tasks, making the data preparation process more efficient and less time-consuming.
In terms of data schema detection, TABLUM.IO is a standout tool that sets it apart from other low-code ETL tools. It doesn't require the installation, configuration, and maintenance of a separate solution. Instead, TABLUM.IO can be used out of the box with ease, and its schema generation capabilities make it faster and more efficient for data ingestion.
Overall, TABLUM.IO is a user-friendly and efficient tool for data engineers and analysts to prepare and transform their data.
